Top 8 Free MLOps Tools

Introduction
Machine Learning Operations (MLOps) is the practice of taking machine learning models from research to real use. It covers everything from preparing data and training models to deploying them and keeping them running smoothly. For a beginner, this can feel like a huge task because there are so many tools, steps, and new terms to learn.
The good news is that you don’t need expensive software or a big team to get started. There are many free and open-source MLOps tools that help you learn by doing. With these tools, you can practise important skills such as versioning data, tracking experiments, creating pipelines, deploying models, and monitoring their performance — the same skills used by professional ML teams.
In this article, we’ll look at the Top 8 Free MLOps Tools for Beginners. These tools are well known in the industry, easy to install, and work with popular machine learning libraries like TensorFlow, PyTorch, and Scikit-learn. By trying them out, you’ll be able to build your own end-to-end MLOps workflow from model training to deployment without spending any money.
1. MLflow
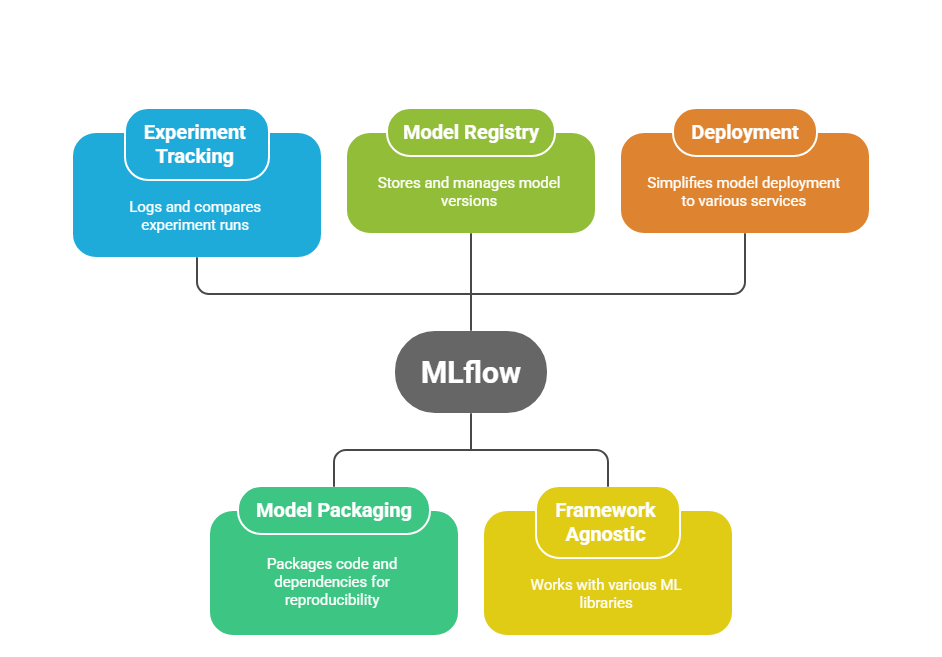
MLflow is a powerful open-source platform designed to help data scientists and machine learning engineers manage the entire lifecycle of machine learning projects — from experimentation to production. Instead of juggling separate tools for tracking experiments, packaging code, and deploying models, MLflow brings everything together in one framework.
- End-to-End Lifecycle Management:
MLflow covers all major stages of an ML workflow — data preparation, model training, evaluation, packaging, deployment, and monitoring. This makes it easier to reproduce results and collaborate across teams. - Experiment Tracking:
With a single line of code, you can log parameters, metrics, artifacts (like model files), and visualizations for every run. The MLflow UI then lets you compare these runs side by side, which is extremely helpful for identifying the best model version. - Model Packaging & Reproducibility:
MLflow introduces a concept called Projects, where you package code, dependencies, and environment specifications. Anyone can then reproduce your experiments on their own machine or a remote server without configuration headaches. - Model Registry:
A built-in model registry stores different versions of a model with staging and production tags. Teams can easily promote or roll back models in a controlled way, similar to version control for code. - Framework-Agnostic:
Unlike some tools tied to a single ecosystem, MLflow works with any ML library — TensorFlow, PyTorch, Scikit-learn, XGBoost, Hugging Face, etc. This flexibility makes it future-proof for learners. - Deployment Made Simple:
MLflow lets you serve models locally as REST endpoints or push them to cloud services like AWS SageMaker, Azure ML, or Kubernetes without rewriting code. - Lightweight and Easy to Start:
Beginners can install it with pip install mlflow and launch a local tracking server with one command. The intuitive web interface lowers the learning curve significantly. - Community and Ecosystem:
MLflow is backed by Databricks and an active open-source community, so you’ll find plenty of tutorials, integrations, and support.
Practical Tip for Beginners:
Start by installing MLflow on your laptop and running its quickstart example. Train a small Scikit-learn model, log metrics, and view them in the MLflow UI. This hands-on exercise will show you how experiment tracking, model packaging, and deployment work together in one platform.
2. Kubeflow
Kubeflow is an open-source MLOps platform built on top of Kubernetes that helps teams design, deploy, and scale machine learning workflows in a production-ready way. Instead of manually wiring together notebooks, scripts, and servers, Kubeflow gives you a structured environment to run and manage everything consistently.
- Kubernetes-Native Architecture:
At its core, Kubeflow leverages Kubernetes’ orchestration capabilities. It packages your ML tasks (data preparation, training jobs, serving endpoints) into containers and schedules them on a cluster automatically. This means you can scale from a laptop demo to a multi-node cloud environment without rewriting code. - Pipeline Orchestration:
Kubeflow Pipelines provide a visual and programmatic way to build reproducible ML workflows. Each step of your workflow—such as data preprocessing, model training, evaluation, and deployment—becomes a pipeline component that can be versioned and reused. - Training at Scale:
It supports distributed training jobs for frameworks like TensorFlow, PyTorch, and MXNet. You can run multiple experiments in parallel, allocate GPUs or TPUs on demand, and monitor resource usage directly in the dashboard. - Model Serving:
Kubeflow integrates with TensorFlow Serving, KFServing, and Seldon Core to deploy models as REST or gRPC endpoints. This lets you roll out new models, perform canary releases, and monitor performance without manual server management. - Integrated Notebook Servers:
You can spin up Jupyter Notebooks inside the Kubeflow environment to experiment with data and code, then seamlessly transition your notebooks into pipeline steps. - Scalability & Portability:
Because it’s based on Kubernetes, you can run Kubeflow on any major cloud provider (AWS, GCP, Azure) or on-premises clusters. This makes it ideal for learning real production workflows without vendor lock-in. - Why It’s Good for Beginners:
- Free and open source with an active community.
- Comes with ready-to-use sample pipelines and templates.
- Provides a realistic “hands-on” experience with production-grade MLOps tools.
- Practical Tip for Beginners:
Start with MiniKF or kind (Kubernetes in Docker) to run a lightweight Kubeflow setup locally. Build a small pipeline—like training a simple Scikit-learn model—and deploy it to see how each component (pipeline step, notebook server, model serving) fits together.
3. DVC (Data Version Control)
DVC is an open-source tool that extends the familiar concepts of Git to the world of data science. While Git is great for versioning code, it struggles with large files such as datasets, model weights, or preprocessed artifacts. DVC solves this gap by letting you version control datasets, ML models, and entire pipelines alongside your code so your work stays reproducible and organized.
- Why Version Control for Data Matters:
In machine learning projects, datasets change frequently. Without tracking, it’s hard to know which version of the data produced which model. DVC links data and code together, making every experiment reproducible — even months later. - How It Works with Git:
DVC creates small “pointer” files (like .dvc files) that live in your Git repo instead of storing huge datasets there. The actual data lives in a remote storage (Google Drive, S3, Azure, local server). When you pull the repo, DVC downloads the exact dataset versions you need. - Core Features:
- Data Versioning: Track large datasets and models just like code.
- Remote Storage: Push and pull data to/from cloud storage or on-prem servers.
- Pipeline Management: Define your ML workflow (data prep → training → evaluation) as a pipeline. DVC detects dependencies and reruns only changed steps.
- Experiment Reproducibility: Every experiment has a snapshot of code + data + parameters.
- Why It’s Good for Beginners:
- Uses a Git-like command-line interface (dvc add, dvc push, dvc repro), so it feels familiar.
- Free and open-source with lots of tutorials.
- Solves a real pain point early on — losing track of data and models.
- Makes collaboration easier: teammates can reproduce your runs exactly.
- Practical Tip for Beginners:
- Initialize a Git repo with your ML code.
- Install DVC (pip install dvc).
- Add your dataset with dvc add data.csv.
- Configure a free remote (like Google Drive or an S3 bucket).
- Push with dvc push.
Now you and your teammates can clone the repo and run dvc pull to get the same dataset and model versions automatically.
4. Metaflow
Metaflow is an open-source framework originally built at Netflix to make it easier for data scientists and engineers to design, execute, and manage machine learning workflows. Instead of requiring you to learn complex DevOps tools, Metaflow wraps best practices for reproducibility, scalability, and versioning into a simple, Python-friendly API.
- Purpose & Philosophy:
Most data scientists know Python and notebooks but may not be comfortable with Docker, Kubernetes, or Airflow. Metaflow bridges that gap. You write your pipeline as plain Python functions; Metaflow takes care of orchestrating steps, storing metadata, scaling compute, and handling failures. - Key Concepts:
- Flows: The overall workflow (for example: data extract → transform → train → evaluate → deploy).
- Steps: Individual tasks decorated with @step inside the flow; each can run locally or in the cloud.
- Data Artifacts: Inputs/outputs automatically tracked between steps.
- Versioning: Every run is versioned automatically with all parameters and data, so you can reproduce or roll back.
- Core Features:
- Simple Pipeline Definition: Just decorate Python functions with @step. No YAML or JSON configs needed.
- Local to Cloud Scaling: Run on your laptop for prototyping; switch to AWS Batch or Kubernetes for heavy jobs with minimal code changes.
- Scheduling & Automation: Integrates with AWS Step Functions for production scheduling or can be run manually.
- Built-in Data Store: Keeps track of inputs/outputs for each run, making debugging and auditing easier.
- Integration-Friendly: Works with TensorFlow, PyTorch, Scikit-learn, and other ML libraries out of the box.
- Why It’s Good for Beginners:
- You don’t need to learn DevOps or container orchestration at the start.
- Python-first design feels natural for notebook users.
- Automatic versioning and logging teach good MLOps habits early.
- Free and open source, with good docs and examples from Netflix.
- Practical Tip for Beginners:
- Install Metaflow with pip install metaflow.
- Follow the “Hello Metaflow” tutorial to build a simple flow with two steps.
- Run it locally, then configure AWS credentials and rerun it on AWS Batch to see how effortlessly it scales.
Metaflow is a gentle but powerful introduction to building production-style ML pipelines without drowning in infrastructure complexity.
5. Weights & Biases – Free Plan
Weights & Biases (often called W&B) is a powerful, cloud-based platform that helps you track, visualize, and collaborate on machine learning experiments. It has become an industry standard for experiment tracking because of its clean interface, flexible integrations, and generous free plan for individuals and small teams.
- Purpose & Philosophy:
Training machine learning models often means trying dozens or hundreds of experiments with different parameters. Without a good tracking system, it’s easy to lose track of what worked and why. W&B solves this by automatically logging metrics, hyperparameters, datasets, and even system resource usage — all viewable in an interactive dashboard. - Key Concepts:
- Runs: Each training run automatically logs metrics (accuracy, loss, F1-score, etc.) in real time.
- Projects: Organize multiple runs into projects to compare them side by side.
- Artifacts: Versioned storage for datasets, models, or other files to ensure reproducibility.
- Reports: Share interactive results with your team or the public.
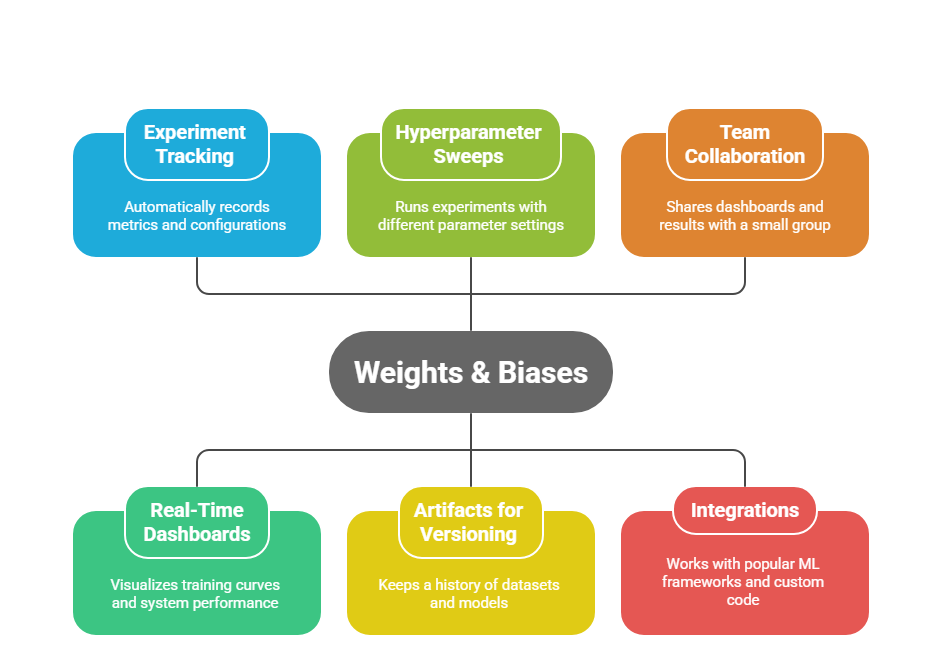
- Core Features (Free Plan):
- Experiment Tracking: Automatically records metrics, config values, and output files.
- Real-Time Dashboards: Visualize training curves, system performance, and parameter sweeps.
- Hyperparameter Sweeps: Run many experiments in parallel with different parameter settings and see which works best.
- Artifacts for Versioning: Keep a history of datasets, models, and pipelines tied to each run.
- Team Collaboration (Limited): Share dashboards and results with a small group for free.
- Integrations: Works out of the box with TensorFlow, PyTorch, Keras, Hugging Face, Scikit-learn, and custom code.
- Why It’s Good for Beginners:
- The free plan gives enough features to learn serious experiment tracking without paying.
- Simple pip install wandb and one-line setup (wandb.init(project=”…”)) to start logging.
- Automatically creates nice visualizations — no need to manually write plotting code.
- Encourages good practices like saving configs, versioning datasets, and documenting results.
- Practical Tip for Beginners:
- Install with pip install wandb.
- Add two lines of code around your training loop to start logging metrics.
- Watch the real-time graphs in your W&B dashboard.
- Compare runs and share results with your mentor or team.
- Example Use Case:
A beginner training a text-classification model can log accuracy, loss, and confusion matrices automatically; after trying different learning rates, they can instantly see which run performed best and export a report of the findings.
Bottom line: W&B’s free plan gives you a professional-grade experiment tracking and visualization tool without the complexity of setting up servers, making it one of the most beginner-friendly MLOps platforms.
6. ZenML
ZenML is an open-source framework that helps you build reproducible, production-ready ML pipelines with simple, Pythonic code. It sits in the middle of your stack and cleanly connects tools you already know (MLflow, Kubeflow, Seldon Core, W&B, Great Expectations, etc.), so you can start locally and scale to real production without rewriting everything.
- What ZenML solves (in plain words):
- Keeps your ML workflow modular (data → train → evaluate → deploy) instead of one giant notebook.
- Makes runs reproducible (same code, same parameters, same artifacts).
- Lets you swap infrastructure (local → Airflow/Kubeflow) and swap tools (e.g., MLflow → W&B) with minimal code changes.
- Core concepts (you’ll see these everywhere):
- step: Decorator that turns a Python function into a pipeline step (e.g., load_data, train_model).
- pipeline: Decorator that wires steps together into a DAG (flow) you can run anywhere.
- Stack: A pluggable set of components that power execution:
- Orchestrator (Local, Airflow, Kubeflow…)
- Artifact Store (Local disk, S3, GCS, Azure…)
- Experiment Tracker (MLflow, W&B, Neptune…)
- Model Deployer (Seldon Core, KServe, BentoML…)
- Secrets Manager (to keep keys/tokens out of code)
- Materializers & Artifact Types: Standardized ways to serialize/deserialize datasets, models, and metrics between steps.
- Caching: Skips recomputation when inputs/params didn’t change; huge time saver while iterating.
- Lineage: Every step/run records what produced what, so you can audit and reproduce.
- step: Decorator that turns a Python function into a pipeline step (e.g., load_data, train_model).
- Key features (why teams use it):
- Python-first SDK + CLI: define pipelines in code, manage stacks via CLI.
- Reproducibility by default: config, params, and artifacts logged per run.
- Tooling integrations: MLflow/W&B (tracking), Great Expectations/Evidently (validation/monitoring), Seldon/KServe (serving), Airflow/Kubeflow (orchestration).
- Local-to-cloud symmetry: prototype on laptop, run the same pipeline on a cluster with a different stack.
- Deployment hooks: push a trained model to a live endpoint (e.g., Seldon Core) as a final step in the pipeline.
- Why it’s great for beginners:
- Low DevOps burden: start with a local stack (everything on your machine).
- Clean structure: steps/pipelines teach good MLOps habits early.
Batteries included: you can add experiment tracking, validation, and serving when you’re ready—no redesign.
7. Seldon Core
What Seldon Core is :
Seldon Core is an open-source framework for serving, scaling, and monitoring ML models on Kubernetes. It turns your trained model (any framework) into a production-ready microservice with metrics, logging, and advanced deployment patterns (canary, A/B, shadow).
- Purpose & high-level idea:
Instead of running a model inside a notebook or a single VM, Seldon Core helps you package that model as a container, declare how it should be served, and then the Seldon operator (running in Kubernetes) creates all the pods, services, and routes needed to serve it reliably at scale. - Core components you should know:
- Seldon Operator — A Kubernetes operator that watches SeldonDeployment custom resources and manages the lifecycle of deployments.
- SeldonDeployment (CRD) — A Kubernetes object where you describe your inference graph (router → transformer → model → combiner, etc.), replicas, resources, and protocol.
- Prebuilt model servers / SDK — Seldon ships with easy server templates (for Scikit-learn, XGBoost, TensorFlow, etc.) and a Python SDK to wrap custom models.
- Inference Graph — A SeldonDeployment can be a chain/graph of components (preprocessor, model(s), postprocessor), letting you compose ensembles or complex pipelines.
- Monitoring & Explainability plugins — Integrations for Prometheus/Grafana for metrics, and tools like Alibi for explainability.
- Key features (what makes it powerful):
- REST and gRPC endpoints for real-time predictions.
- Autoscaling and horizontal scaling through Kubernetes.
- Advanced release patterns — canary rollouts, A/B testing, shadow traffic.
- Request/response logging and custom metrics (easy Prometheus scraping).
- Model routing & ensembles — route requests to different models or combine outputs.
- Explainability & monitoring integrations — plug in explainers and drift detectors.
- How it works (typical workflow):
- Package your model: either use a prebuilt server and point it to a modelUri, or wrap your model with the Seldon Python SDK and build a Docker image.
- Push the image (if you built one) to a container registry.
- Create a SeldonDeployment YAML manifest that declares the graph, replicas, and resource limits.
- Apply the manifest to your Kubernetes cluster; the Seldon operator creates pods, services, and routes.
- Call the exposed REST/gRPC endpoint and monitor metrics/logs (Prometheus/Grafana).
- Quickstart tips for beginners:
- Run a local cluster with minikube or kind to experiment.
- Use Seldon’s prebuilt servers to avoid containerizing your model at first — just give a modelUri.
- Install the Seldon operator using the official docs (Helm or kubectl) rather than guessing commands.
- Start with 1 replica and minimal resource requests; scale later.
- Enable Prometheus scraping to get immediate visibility into request rates and latencies.
(That tells Seldon to use a prebuilt sklearn server and serve the model from your storage.)
- Common beginner pitfalls & how to avoid them:
- Kubernetes complexity: practice with a small local cluster first.
- Containerization overhead: use prebuilt servers initially, then learn to Dockerize.
- Resource limits & probes: forgetting liveness/readiness or CPU/memory limits can cause instability — always set them.
- Networking/ingress confusion: talk to Seldon services via the cluster IP or configure an ingress/service mesh (Istio) for external access.
- When to use Seldon Core (use cases):
- Real-time inference with low latency requirements.
- Canary/A-B testing of new models in production.
- Serving ensembles or chained preprocessing/postprocessing.
- Teams that need production observability (metrics, logs, explainability).
Bottom line: Seldon Core is a production-grade, Kubernetes-native model serving solution. For beginners it’s a great way to learn how real systems deploy and manage models in production — start with a local cluster and prebuilt servers, then graduate to custom containers, traffic splitting, and monitoring as you gain confidence.
8. Neptune.ai – Free Tier
Neptune.ai is a metadata store and experiment tracking platform for machine learning and deep learning projects. It acts like a “single source of truth” for all your model-building work — metrics, parameters, code versions, artifacts, and results — so you and your team never lose track of what you ran and why. Its free tier is generous enough for personal projects or small teams, which makes it an excellent choice for beginners.
What it solves (in simple words):
- In ML projects you often run many experiments with different hyperparameters, data subsets, or architectures.
- Without a central log, you can’t easily reproduce the best run or compare experiments over time.
- Neptune.ai stores metadata about every experiment and organizes it visually, so you always know which run produced which result.
Core Concepts:
- Projects: Top-level container for all runs and metadata. You can have multiple projects (e.g., “Image Classification,” “NLP Experiments”).
- Runs: Each execution of your training script becomes a run with its own ID. All metrics, parameters, and artifacts are logged here automatically.
- Metadata: Everything about your run — metrics, hyperparameters, environment, code version, predictions, logs.
- Artifacts: Files associated with the run — model weights, plots, confusion matrices, datasets, logs, checkpoints.
- Dashboards: Interactive UI to explore runs, compare charts, and drill down into details.
Key Features of the Free Tier:
- Unlimited metrics and parameters logging for personal use.
- Artifacts storage to keep models, logs, and plots tied to each run.
- Interactive dashboards for visualizing training progress in real time.
- Team collaboration for a small group (share runs and dashboards).
- Integrations: Works with TensorFlow, PyTorch, Scikit-learn, XGBoost, LightGBM, Keras, Hugging Face, and custom scripts.
- Versioning: Keeps track of code versions, environment, and datasets used, making experiments reproducible.
- Notebooks support: Log from Jupyter notebooks easily.
Why It’s Good for Beginners:
- Quick start: Just pip install neptune and add a couple of lines to your training script.
- No self-hosting required: Everything runs in the cloud; no servers to manage.
- Visual comparison: Automatically plots metrics across runs so you see which experiment worked best.
- Encourages best practices: Versioning, organized artifacts, reproducibility from day one.
- Free tier fits learning stage: Enough storage and features to cover most beginner and small-team use cases.
- Bottom line:
Neptune.ai’s free tier gives you a cloud-hosted, full-featured experiment tracking and metadata store without the setup headaches. It’s one of the easiest ways for beginners to practice proper experiment management and reproducibility — skills that are essential for real-world MLOps.
Conclusion
Mastering MLOps doesn’t have to start with expensive tools or complex enterprise platforms. The eight free options we’ve covered — MLflow, Kubeflow, DVC, Metaflow, Weights & Biases, ZenML, Seldon Core, and Neptune.ai — give beginners everything they need to practise real versioning data and models, building pipelines, tracking experiments, and deploying models at scale.
By experimenting with these free tools, you’ll learn the same concepts and practices used by leading tech companies: reproducibility, automation, monitoring, and collaboration. Start small — run a model locally, log your metrics, version your data — then gradually add orchestration, deployment, and monitoring as your projects grow. This hands-on approach will build a strong foundation in MLOps and prepare you for production-grade machine learning environments.
Whether you’re a student, a solo learner, or part of a small team, these platforms let you gain practical skills without financial barriers, so you can focus on learning rather than setup costs. Combine two or three of them (for example, ZenML for pipelines, MLflow or Neptune for tracking, and Seldon Core for deployment) and you’ll already be working with an end-to-end MLOps stack that mirrors industry standards.
FAQs
What is MLOps?
MLOps (Machine Learning Operations) is the practice of managing machine learning models from development to deployment and monitoring in production.
Why are free MLOps tools useful for beginners?
They let you practise real-world workflows without spending money, so you can learn and build skills quickly.
Which is the most beginner-friendly MLOps tool?
MLflow is often recommended first because it’s easy to install, simple to use, and works with any ML library.
Do these free tools work with TensorFlow and PyTorch?
Yes. Most tools on the list (MLflow, W&B, ZenML, etc.) support TensorFlow, PyTorch, Scikit-learn, and many more.
Can I use multiple MLOps tools together?
Absolutely. For example, you can use ZenML for pipelines, MLflow for tracking, and Seldon Core for deployment.
Do I need Kubernetes knowledge to use these tools?
Only for Kubernetes-based tools like Kubeflow or Seldon Core. Others run locally without Kubernetes.
Are these tools truly free?
Yes. All listed tools have free or open-source versions. Some also offer paid plans for advanced features.
What is experiment tracking in MLOps?
It means recording all your model runs, metrics, parameters, and artifacts so you can compare and reproduce results.
Which tools are best for experiment tracking?
Weights & Biases (W&B), MLflow, and Neptune.ai are widely used for this purpose.
What is a pipeline in MLOps?
A pipeline is a series of connected steps (like data prep → training → evaluation → deployment) run automatically.
Which tool is good for building pipelines?
ZenML and Metaflow are great for building simple, reproducible pipelines.
How does DVC help in MLOps?How does DVC help in MLOps?
DVC (Data Version Control) keeps track of datasets and models just like Git keeps track of code.
What’s the difference between MLflow and Kubeflow?
MLflow focuses on experiment tracking and model packaging. Kubeflow is a full Kubernetes-based platform for pipelines and deployment.
Do I need to code to use these tools?
Yes, basic Python knowledge helps. Most tools have Python-friendly APIs.
Which tool helps deploy models easily?
Seldon Core is designed for deploying and scaling models in Kubernetes.
What is metadata in MLOps?
Metadata is all the information about your experiment — parameters, metrics, code version, and artifacts.
Which tool stores experiment metadata?
Neptune.ai is specifically designed as a metadata store for ML experiments.
Can I collaborate with others using free tiers?
Yes. Tools like W&B and Neptune.ai allow small teams to share dashboards and results on free plans.
Do these tools support cloud storage?
Yes. Most integrate with S3, GCS, Azure, and other cloud services.
What is model versioning?
It’s keeping different versions of your trained models so you can roll back or compare them later.
Which tool is best for model versioning?
DVC and MLflow are popular choices for model versioning.
Are these tools safe to use for company projects?
Yes. The open-source versions are widely used, but always check licenses and security requirements for your company.
Do I need GPUs to use these tools?
No. The tools work regardless of your hardware. You only need GPUs for heavy training tasks.
Can I run these tools on my laptop?
Yes. Most can run locally. Kubernetes-based tools can run on a local cluster like Minikube.
What’s the easiest way to learn MLOps with these tools?
Start with one tool (like MLflow or W&B), run a small project, then gradually add more tools for pipelines and deployment.
Do these tools help with monitoring models in production?
Yes. Tools like Seldon Core support metrics and monitoring. You can integrate Prometheus/Grafana for dashboards.
Is there documentation or tutorials for each tool?
Yes. Each tool’s website has step-by-step guides, examples, and community support.
How much time does it take to learn these tools?
It varies, but you can get comfortable with basic features of most tools in a few days to a couple of weeks.
Can students use these tools for research projects?
Yes. They’re ideal for students to track experiments, version data, and build reproducible ML workflows.
What’s the best approach to choose a tool?
Identify your main need (tracking, pipelines, deployment) and start with the simplest tool for that. Add more as your project grows.